
23년도 주요 서비스 장애 사례
지역적 문제일수도 있지만, 매우 큰 매머드 회사의 장애는 세계적인 장애라고 본다. 2023년 발생한 주요 서비스 장애 사례를 보면, 마이크로소프트, AWS 같은 쟁쟁한 업체의 아무리 정교한 환경에서도 성능 저하와 네트워크 중단이 나타나고 서비스 중지로 이어질 수 있다.

시스코 산하의 인터넷 및 클라우드 트래픽을 추적하는 네트워크 인텔리전스 기업 사우전드아이즈(ThousandEyes)에 따르면, 2023년 한 해 동안 7건의 심각한 서비스 장애가 발생했고, 성능 저하와 트래픽 속도 저하로 사용자와 기업에 영향을 미쳤다.
작은 변경 사항이 전 세계 네트워크에 큰 혼란을 야기했고, 업체들은 서비스 복구를 위해 분주하게 움직였다. 사우전드아이즈는 “2023년에 SaaS 애플리케이션, ISP, 기타 지원 인프라에서 많은 서비스 장애가 발생했다. 이는 서비스 중단의 여파를 최소화하고, 더 예측 가능한 성능을 위해 서비스와 애플리케이션을 사전에 최적화해야 한다는 중요한 교훈을 남겼다"라고 분석했다.

23년도는 아니지만 22년 말 한국에서도 매우 큰 장애 사건이 있었다.
SK C&C 판교 데이터센터 화재 사건
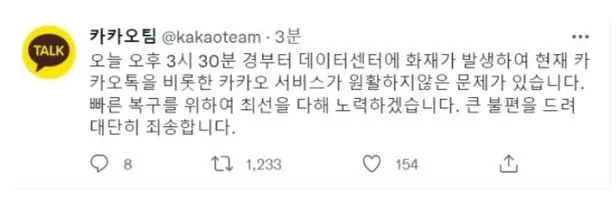
2022년 10월 15일 15시 30분경, 경기도 성남시 삼평동에 위치한 SK주식회사C&C 판교캠퍼스 A동 지하 3층 전기실에서 화재가 발생했고 이 과정에서 서버 작동에 필요한 전원 공급이 끊겨 카카오의 서비스를 비롯한 해당 IDC에 입주한 모든 서비스들이 다운되어버린 사건이다.
대국민 서비스인 카카오가 분산이 없는 단일 지하에 서버가 모두 존재한다는 것 자체도 큰 충격이였다. 많은 돈을 벌었지만, 설마설마로 대응한 과거를 반성하고 데이터를 안전하게 분산하겠다고 약속했지만 요즘 내부문제와 비리 사태로 인해 아직은 미지수이다.
- 카카오톡 비즈 채널, 예약, 선물하기(상품권 · 금액권) 등 카카오 서비스를 활용 중이었던 매장은 카카오를 통한 예약, 상담, 결제 등 기본적인 영업조차 불가능한 상황이 발생했다.
- 카카오톡으로 순번대기표를 발송하는 일부 가게들이 알림을 발송할 수 없게 되었다.
- 카카오 T의 먹통으로 카카오T 택시기사, 대리기사, 퀵서비스 기사는 콜을 받지 못하여 원활한 근무가 불가능해 수익 창출의 차질이 불가피하다.
- 카카오 T의 먹통으로 인해 카카오바이크와 전동킥보드를 반납할 수 없는 상황이 발생했다.
- 카카오 T 주차를 통해 입차한 차량이 출차를 하지 못하는 상황이 발생했다.
- 페이스톡을 사용하는 아이돌 영상통화 팬싸인회는 연기되거나 다른 플랫폼을 통해 진행된다.
- 블라인드에서는 겨우 로그인했더니 대출이 사라졌다며 갚지 않아도 되는거냐는 유머성 게시글이 올라왔다.
- 멜론 또한 먹통이 되었다.
지난 한 해 동안 장애가 가장 많이 발생한 업계는 인터넷 서비스 업체(ISP)였고, 클라우드 서비스 업체(CSP)가 그 뒤를 이었다. 이는 기업이 클라우드 인프라를 더 많이 활용하고 있다는 의미이기도 하다. 시간순으로 정리한 2023년의 주요 ‘서비스 중단’ 사건·사고는 다음과 같다.
AWS의 2시간 서비스 장애
6월 13일 AWS에서 미국 동부 해안의 여러 서비스에 영향을 미친 2시간 이상의 장애가 발생했다. 해당 장애는 저녁에 시작됐고 몇 시간 후 해결됐다. 사우전드아이즈는 AWS 서버로 연결되는 네트워크 경로에서 높은 지연 시간, 패킷 손실 등의 문제를 관찰하지 못했다고 밝혔다. 하지만 AWS에서 호스팅되는 애플리케이션의 가용성에 영향을 미친 지연 시간 증가, 서버 시간 초과, HTTP 서버 오류가 발견됐다.
사우전드아이즈에 따르면, 해당 장애는 영향을 받은 애플리케이션에 접속하려는 사용자의 응답 시간 증가, 시간 초과, HTTP 5XX 서버 오류로 나타났다. 사고 발생 직후 AWS는 문제 원인이 용량 관리 하위 시스템이라고 밝혔으며, 이 시스템이 람다(Lambda), AWS 관리 콘솔(AWS Management Console) 등을 비롯한 여러 서비스의 가용성에 영향을 미쳤다고 설명했다. 또한 영향을 받은 서비스에서 오류율과 지연 시간 증가가 발생했으며, 그 결과 호스팅 위치나 사용자에게 서비스를 제공하는 위치와 관계없이 AWS 서비스를 사용하는 애플리케이션의 서비스 가용성 문제가 발생했다.
사우전드아이즈는 "AWS의 사례는 오늘날 애플리케이션과 서비스가 의존하고 있는 복잡한 상호의존성 웹을 보여준다. 이런 종속성 중 상당수는 기업이 직접 사용하는 서비스의 종속성일 수 있기 때문에 간접적이거나 숨겨져 있을 수 있다”라고 말했다.
MS 365의 전 세계적 접속 장애
2023년 1월 25일 마이크로소프트 사용자는 약 90분 동안 애저, 팀즈, 아웃룩, 쉐어포인트 등의 마이크로소프트 서비스에서 글로벌 연결 문제를 겪었다. 네트워크에서 높은 수준의 패킷 손실이 발생하면서 연결에 문제가 생겨 마이크로소프트 및 기타 서비스를 쓸 수 없게 됐고, 아울러 HTTP 및 DNS 시간 초과가 발생했다.
사우전드아이즈의 분석에 따르면 상당한 수의 BGP(경계 게이트웨이 프로토콜) 경로 변경으로 패킷 손실이 발생했다. BGP는 네트워크 트래픽이 어떤 경로로 이동할지 알려주는데, 정보가 부정확하면 트래픽이 잘못된 경로로 이동할 수 있다. 트래픽에 가장 적합한 경로를 찾기 위한 변경이 여러 번 반복되면서 심각한 이탈(경로 테이블 불안정)이 발생했다. 사우전드아이즈는 “트래픽 경로의 급격한 변경 그리고 트랜짓 업체 네트워크를 통한 대규모 트래픽 이동이 합쳐져 높은 수준의 패킷 손실이 발생한 것으로 보인다"라고 설명했다.
해당 서비스 중단이 전 세계에 미치는 영향과 사용자 피해는 상당했지만, 마이크로소프트의 신속한 복구는 높이 평가할 만하다. 사이전드아이즈는 “마이크로소프트가 신속하게 복구하기 시작했다는 점에서 문제에 대한 충분한 가시성과 롤백 및 수정 계획이 있음을 알 수 있었다. 서비스 중단 시간은 운영팀이 직면한 장애 범위를 고려할 때 적절한 조치를 하고 있는지 확인한 결과일 수 있다”라고 말했다.

MS 아웃룩의 서비스 중단
하지만 마이크로소프트 아웃룩 사용자는 얼마 지나지 않아 또다시 서비스 중단을 겪었다. 2월 7일 북미, 유럽, 아시아의 마이크로소프트 사용자는 몇 시간 동안 아웃룩 접속 문제를 겪었으며, 특히 미국에서 가장 큰 영향을 받았다. 사우전드아이즈에 따르면 해당 서비스 중단은 전 세계적으로 발생했지만, 이전 사고와 달리 심각한 패킷 손실, 지연 시간 또는 비정상적인 라우팅이 관찰되지 않았다.
네트워크가 문제의 근본 원인이 아닐 수 있다는 의미다. 대신 사우전드아이즈는 “장애가 발생한 동안 서비스 응답 시간 초과, 페이지 로드 시간 증가 등 애플리케이션 관련 문제를 나타내는 증상을 관찰했다”라고 설명했다.
하루에 두번 장애 일으킨 영국 인터넷 업체
2023년 4월 4일 영국의 인터넷 업체 버진 미디어(Virgin Media)에서 발생한 두 차례 서비스 중단의 주요 원인은 BGP 라우팅인 것으로 밝혀졌다. 해당 장애는 버진 미디어 영국 네트워크와 글로벌 인터넷 서비스에 영향을 미쳤다. 같은 날 두 차례나 장애가 발생했으며, 몇 시간씩 지속됐다.
이날 장애는 실행 가능한 BGP 경로 부족이 트래픽 손실을 초래한 것이었다. 사우전드아이즈에 따르면, 2번의 서비스 중단에서 네트워크 경로 철회, 트래픽 손실, 간헐적인 서비스 복구 기간 등 유사한 특성이 관찰된다. 첫 번째 장애가 일반적인 유지보수 시간대(현지 시각으로 12시 30분)에 시작됐다는 점을 고려하면 서비스 업체의 네트워크 상태 변경에 따라 발생한 것으로 보인다. 거의 동일한 장애가 당일 오후 재발했다는 사실은 첫 번째 장애의 트리거 메커니즘이 완전히 밝혀지지 않았거나 해결되지 않았음을 나타낸다”라고 설명했다.
슬랙의 서비스 성능 문제
슬랙은 서비스 성능 문제가 발생했지만, 완전히 중단되지는 않았다. 하지만 서비스 장애로 슬랙 사용자는 원하는 작업을 완료하기 어려웠다. 2023년 8월 2일 슬랙 사용자는 약 2시간 동안 파일 업로드 문제, 이미지가 흐릿하게 표시되는 문제를 겪었다. 몇몇 사용자는 페이지 로드 시간 지연, 로그인 불가, 전반적인 불안정성 등의 불편을 겪기도 했다. 서비스를 사용할 수는 있지만 무용지물인 상태였다.
사우전드아이즈의 분석 결과, 슬랙에 접속하려는 전 세계 사용자에게 HTTP 500 서버 사용 불가 오류가 증가하고 페이지 로드 시간이 평소보다 길어졌다. 추가 조사를 통해 일반적으로 약 28개의 개체가 로드돼야 하는 슬랙 웹 클라이언트가 15개만 로드되고 있다는 사실이 밝혀졌다. 사우전드아이즈는 슬랙의 문제가 애플리케이션 백엔드 문제와 관련 있을 가능성이 높다고 분석했다.
또한, 슬랙의 서비스 장애와 관련해 2가지 흥미로운 점을 언급했다. 첫 번째는 일반적으로 예약된 작업을 나타내는 정시에 발생했다는 점이고, 두 번째는 일상적인 데이터베이스 클러스터 마이그레이션 중 실수로 인한 데이터베이스 용량 감소가 근본 원인이라는 점이다. 사우전드아이즈는 “예정된 작업과 사용자 요청이 합쳐져 데이터베이스 요청이 점차 늘어나 대기열이 막힐 지경에 이르렀다. 들어오는 요청으로 데이터베이스 클러스터의 용량이 의도치 않게 줄어들었고, 그 결과 슬랙의 일부 작업에서 오류가 발생했다”라고 설명했다.
결제 시스템 먹통된 ‘스퀘어’
2023년 9월 8일 비접촉식 결제 단말기 및 서비스 업체 스퀘어(Square)에서 18시간 이상 서비스 장애가 발생했다. 이 서비스의 사용자는 거래를 처리할 수 없었다. 장애 원인은 백엔드 연결 문제 때문으로 파악됐다. 사우전드아이즈에 따르면, 서비스 장애가 발생한 시간 동안 이체와 기타 결제 처리 중이던 자금을 처리하지 못했다. 이 장애의 여파가 더 커진 이유다.
스퀘어 사용자는 결제가 완료된 것처럼 보이지만, 비즈니스 계정에 전달되지 않거나 단말기 연결이 끊기는 등의 문제가 발생했다. 사우전드아이즈는 “간헐적인 연결 끊김과 503 ‘서비스 사용 불가’ 오류가 관찰됐다. 성능 저하 패턴으로 봤을 때 근본 원인은 내부 라우팅 또는 유사한 백엔드 시스템일 수 있다”라고 설명했다. 이후 스퀘어는 보고서를 통해 문제 원인이 백엔드 시스템, 특히 DNS라고 밝혔다. 스퀘어는 “내부 네트워크 소프트웨어에 몇 가지 표준 변경 사항을 적용하는 동안 시스템이 제대로 통신하지 못했고, 결국 장애가 발생했다”라고 설명했다.

정전으로 인한 워크데이와 클라우드플레어의 서비스 장애
2023년 11월 2일 워크데이와 클라우드플레어의 서비스가 중단됐다. 사우전드아이즈는 두 업체의 서비스 중단이 서로 관련 있는 것으로 추정했다. 두 사건의 공통점은 미국 오리건주 포틀랜드에 있는 플렉센셜(Flexential) 데이터센터의 부분적인 주전원 정전이다. 클라우드플레어는 사후 보고서에서 (데이터센터의 정전이) 장애 원인이라고 밝혔으며, 워크데이도 데이터센터를 원인으로 지목했다.
두 업체의 분석, OSINT(오픈소스 인텔리전스 도구), 사우전드아이즈의 보고서를 종합하면 두 사건이 서로 관련돼 있음을 알 수 있다. 클라우드플레어는 사고 분석 보고서를 발표했고, 워크데이는 자세한 내용은 밝히지 않았지만, 두 업체는 백업 정전 문제와 불안정한 전력으로 추가 문제가 발생해 서비스 복구가 평소보다 오래 걸렸다고 설명했다.
사우전드아이즈에 따르면, 클라이언트와 서버 간의 상호작용이 중단될 때 발생하는 ‘페이지 콘텐츠가 일치하지 않음’ 오류와 로그인 요청 시 정적 유지 관리 페이지로 즉시 리디렉션되는 현상이 나타났다. 사우전드아이즈 테스트 결과 주목해야 할 또 다른 요소는 정적 콘텐츠가 AWS에서 제공되고 있다는 점이다. 서비스 중단 이전에는 워크데이 콘텐츠가 클라우드플레어를 통해 제공됐다.
오토모 카츠히로의 'AKIRA' 원작과 애니메이션
무너진 도쿄, 비밀 프로젝트! 오토모 카츠히로가 1982년부터 1990년까지 코단샤의 청년대상 만화잡지 〈영 매거진〉에 연재한 사이버펑크에 영향을 받은 만화로 출판사에서 선전 문구로 내세운
memebro.kr
오프닝시퀀스의 거장 'Kyle Cooper (카일쿠퍼)'
Opening Sequence 영화의 전체에 생명을 불어넣어주는 오프닝 시퀀스 지금은 모션그래픽 디자인의 굵직한 장르이며, 영화 산업의 사업으로 자리 잡은 인트로 무비, 오프닝 시퀀스, 타이틀 시퀀스. 지
memebro.kr
웨스앤더슨의 미장센 '앵글과 색감에 올인하는 영화감독'
영화감독 '웨스 앤더슨'의 재미있는 '대칭' [ Symmetry ] '그랜드 부다페스트 호텔'로 유명한 감독 웨스 앤더슨. 영화의 색감으로도 유명하지만, 카메라 앵글의 고집으로도 유명합니다. 미학을 고집
memebro.kr
일본의 80년대 버블경제 대중문화 매시업
일본의 전성기 80년대 일본의 버블시대인 1980년대 일본의 대중문화는 한국의 90년대와 매우 비슷하다. 그만큼 유행과 대중문화를 따라갔기 때문이기도 하다. 음악, 영화, 공중파 예능방송, 특히
memebro.kr
'OTT 대중문화 스토리' 카테고리의 다른 글
| 왕좌의 게임 촬영현장 정겨운 뒷 모습 (2) | 2024.05.15 |
|---|---|
| 헐리우드 배우 출연료 순위 (2023년) (2) | 2024.05.15 |
| '넷플릭스'의 영화데이터는 어디에서 오는 것일까? (1) | 2024.05.15 |
| 내수용, 수출용 영화포스터 퀄리티의 차이 (1) | 2024.05.15 |
| 티빙 웨이브 왓챠 생존싸움이 도래했다. (0) | 2024.05.15 |
| 음악산업의 '멀티 레이블'이란? (2) | 2024.04.26 |
| 일본의 80년대 버블경제 대중문화 매시업 (0) | 2024.02.06 |
| 오토모 카츠히로의 'AKIRA' 원작과 애니메이션 (2) | 2024.02.04 |






